
Hi all,
QualCoder uses pdfminer.six for the pdf text extraction. Thanks to the maintainers of that project.
People have asked that direct pdf coding be an option. I can see the advantage is when coding text, you can see where the text is located near other text and images on the page. However, this is quite a challenging request.
The challenges: Unlike Microsoft Word or LibreOffice Writer or plain text documents, Pdfs are very different. They are designed in a print format and not designed to have text extracted. Some Pdfs may present the text as a full page image – so text extraction is not possible without using optical character recognition software. This will not be an option in QualCoder -you would have to do this separately and import the plain text. Where there is text on a Pdf page, the text does not naturally flow from one bunch of words to the next like in a Word document. Instead the text is displayed in text box chucks with x and y coordinates to position each text chunk on the page. Text extraction, like using pdfminer, estimates what the next flowing bit of text is, based on these x, y coordinates. This can be good and it can be wrong sometimes too.
I am experimenting with displaying a pdf, within the Qt graphics interface that is used by QualCoder. This uses pdfminer, so I work within the limitations of pdfminer and my limitations of re-interpreting a pdf and using pdfminer. The intention is to allow some text coding directly using a mouse with the pdf.
So far, pdf rendering is adequate I think, to be able to perform text coding.
There are quite a few limitations regarding displaying the graphics – Images and Polygon shapes. Pdfminer does not find all the images on a page and some images appear to be like photo negatives. Often images have a mask to display a portion of the image and not the full image – I cannot work this out yet. Other problems I have come across, is the order of displaying items, particularly, lines, rectangles, curves and images when overlapping. Curves are polygons which require extra instructions to display correctly. I have selected one font to display text as using Pdf fonts is not possible for now. Also, each character within a text box can have its own formatting (colour, size, emphasis), so most of this is ignored and formatting is estimated for the entire text chunk.
This is an example pdf page with a lot of graphics (images, lines ,rectangles, and curve objects). My experimentation with pdfminer is on the right, the original is on the left..
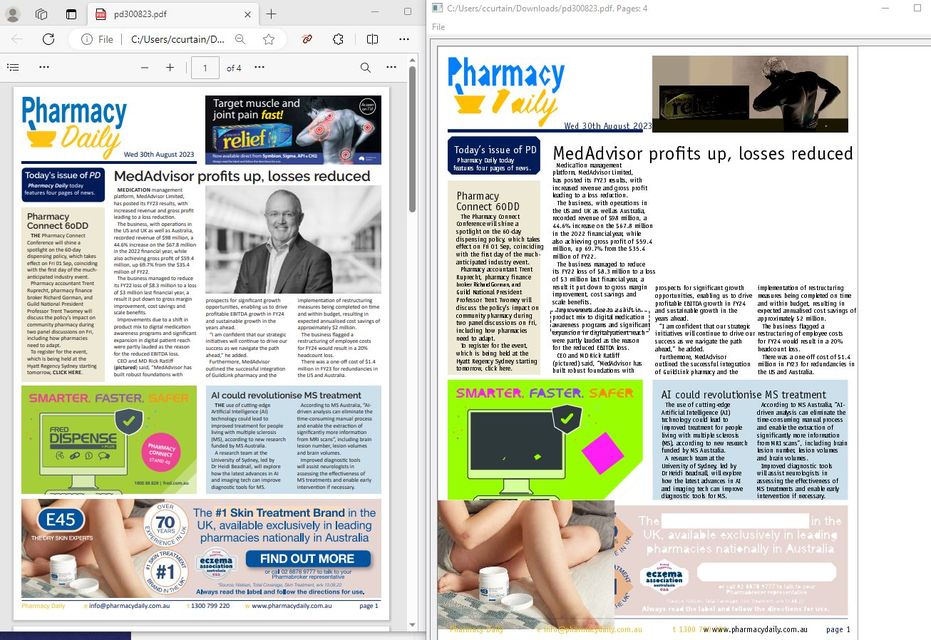
Below is an example of a primarily text filled pdf. The rendering is a lot more similar to the original. The image on the right is my experimentation and the image on the left is the original. At the bottom of the image you can see I added some check boxes to show or hide some of these additional objects (text, lines, rectangles, curves, images) that are rendered on the page.

Next I am trying to select text. The approach for now is to drag the mouse over an area to select the individual text boxes that make up the text portions of the pdf. Then try to match those with the plain text import of the pdf. This will be a first approach to then apply coding to the text of those selected text boxes.
